
![]()
by Larry Wu and Brady Huang
https://members.tripod.com/~ke6bfu/research.html
Brady Huang
Research Paper:
The Internet, the
History, the Web
 |
What is the Internet? It seems that this word is now commonly heard and seen in the lexicon of the English language. So what defines the great realm called the Internet? Is it the electronic mail capabilities or the World Wide Web? The Internet does not consist solely of the World Wide Web or e-mail, as some people may believe. The Internet is a broad term for all the different electronic resources and the computer servers and clients actively storing and relaying information. These resources including different categories of information storage and transfer like FTP, Telnet, electronic mail, gopher, and the USENET. At first glance these terms seem strange and confusing, but like the Web they are simply alternate means of relaying information throughout the Internet. They tend to be less user-friendly and less graphics-oriented than the World Wide Web hypertext interface because they consist of dull text-only applications. The hypertext capabilities of the Web allow Web documents to be linked to others by means of hypertext links in the form of the mouse clickable text or graphics. These documents are accessed by programs, known as Web browsers, specially designed to view material prepared for the Web. In essence, the Web has been the most popular method of displaying information that may be useful both educationally and professionally.
First there are a few terms that must be defined and cleared up. Even I had some misconceptions about some of the common Internet jargon until I found their precise definitions on the Internet. The Internet (upper case I) is the collection of inter-connected networks that use TCP/IP protocols and the descendent of the original government ARPANET of the 60's and 70's. Before I delve into the history of the Internet and any more enigmatic Internet terminology, let me define a few more basic terms. The basic unit that makes up the Internet is the network. A network is simply comprised of at least two computers, connected in such a way that they can share resources. If two or more networks are connected to each other, an internet (lower case I) is the result. The Internet is the result of all these inter-connected internets around the world. There are also Intranets, which are private networks within companies or organizations that utilize the same programs to access the public Internet, but can only be used by the people working within the company or organization. Many companies use some of the same popular Internet tools for private networks such as Web servers, except that they can be accessed by employees only. An Intranet does not have to be an internet though; it could just be a single private network.
There are many types of server programs and protocols that make up the Internet. As I have mentioned before, the common ones are FTP, Telnet, electronic mail, gopher, or the USENET. FTP is short for File Transfer Protocol, which is a client-server protocol for transferring files between computers. A server is a program on a networked computer that serves, links, and responds to the requests of client programs, like those on home or office computers. A client program is one that obtains information from the server. The server and client talk to each other using a server-client protocol like FTP. The term server often refers to the computer itself that is running the server program. An example of a server would be our school server which contains personal student folders and links us to the rest of the Internet community. Web browsers access FTP servers to download files. When the annoying yet common message "FTP error ... too many anonymous users logged in" appears, this indicates that the server program is already responding to the maximum number of client programs.
Telnet is a terminal emulation protocol, which allows one to make a terminal connection to a remote server on the Internet. Basically, this means that you can log in to a server elsewhere by telnetting. However this means that you must run a telnet client on your computer and a telnet server on the other computer. Telnet servers run on UNIX, an operating system (OS). A computer operating system is the very basic software that runs a computer and all other software like word processors and other applications. Macintosh, DOS, and Windows are common office and home computer operating systems. UNIX is designed to accommodate many users at the same time and has TCP/IP built-in. It is the most common operating system for servers on the Internet. TCP/IP is an acronym for Transmission Control Protocol/Internet Protocol. It is the set of protocols that make up the Internet. Although it was created for UNIX, TCP/IP software is now available for the major operating systems. Today, if you want true high-speed Internet access, your computer must have TCP/IP software.
Many college networks are maintained by UNIX-based machines which allows students and professors to access their e-mail accounts and saved files from different locations across the world simply by telnetting into the server. However, our e-mail server does not operate on UNIX. Instead, it runs on the Macintosh platform, which does not allow us to telnet into the server and access our accounts from locations outside the school. Our First Class system uses a more graphics oriented and user-friendly interface as opposed to the text-only Pine or Elm mail systems that colleges use.
Gopher is yet another protocol for distributed information delivery. Gopher clients give access to this information using a menu-driven delivery system without any hypertext capabilities. This means that Gopher documents cannot lead to other documents directly through links in the documents themselves. Everything is arranged by folders or directories that lead to either documents or more folders. However, because Gopher sites lack the clutter of typical Web pages, they are a much easier and more efficient way of finding and retrieving information. Thousands of Gopher servers still exist today. The usefulness and success of the Gopher will keep it going in the future even as it is being overshadowed by fancy Web sites. Our research site uses many Gopher sites as a source of data and information as well as the typical hypertext sites.
The electronic mail system and USENET are used less for transferring data and files, but are used more as personal communication and forums for discussion. E-mail allows users with e-mail accounts, like home addresses, to send messages to each other. Files can be attached to individual messages as well, so that the receiver can download the file. The USENET is a public forum not unlike like a bulletin board. The USENET consists of alphabetically organized discussion groups called Newsgroups ranging from government and politics to recreation and sports. Files and images can be posted electronically on the USENET for public use. Because the USENET is accessed by many people, anyone who posts a message is always subject to public criticism. This may result in "flames" or offensive messages sent to the a person's e-mail account. A flame war occurs when an online discussion, or chat, degenerates into a series of personal attacks against the debaters, rather than the discussion of the positions for which they are debating. This usually occurs less in the well-maintained Newsgroups where there is an understood agreement of courtesy, but getting flamed is always a risk you take when expressing opinions or beliefs on the USENET. I am sorry to say that flaming has reached our e-mail system in a way. Even though it occurs on a much smaller scale than the USENET, one may notice personal attacks that go on in the various discussion folders. In general, the USENET is somewhat like a public rest room. You can choose to write offensive messages on the walls or write nothing at all. Fortunately, there are always members of the USENET community who are kind enough to supply information and answer questions without the public slander.
Our very own Thacher network uses the TCP/IP protocol. A network is often divided into Local Area Networks, or LANs. A LAN is a computer network limited to an immediate area, usually the same building or floor of a building. A LAN would be like a dormitory or any one of the computer labs. LANs are commonly networked by Ethernet, which handles about ten million bits per second (bps) which is about a megabyte per second or about one floppy disc per second. Every computer on the network has a unique IP number, sometimes referred to as a "dotted quad." The IP number identifies a computer by four numbers separated by periods. If a machine does not have an IP number, it is not really on the Internet. Many machines have one or more domain names that exist over IP numbers, a method identification that is easier for most people to remember.
*******
Having investigated much of the Internet terminology, it is important to explore just where and when the Internet came into existence. In 1957, USSR launched the first artificial earth satellite into space. The release of Sputnik into orbit around the earth caused a great deal of alarm in the US. As a result the US Defense Advanced Research Projects Agency (now ARPA) was born within the Department of Defense. It was created to establish a US lead in science and technology that could be applied to military uses. ARPA was one of the bodies instrumental in creating the concept of the Internet and funded the research and development of Internet facilities for many years.
In 1962, Paul Baran of RAND Corporation wrote "On Distributed Communications Networks" and invented the idea packet switching (PS) networks. Packet switching is the way data is moved around on the Internet. All data coming out of a machine is divided into chunks. Each chunk has the address of its source and its destination. This enables chunks of data from many different sources to commingle on the same lines and be sorted and directed toward their respective destinations by special machines along the way. This way many people can use the same lines simultaneously.
In 1965, the Advanced Research Projects Agency sponsored a study on "cooperative network of time-sharing computers." The TX-2 computer at the Lincoln Lab of the Massachusetts Institute of Technology and the Q-32 computer at the System Development Corporation in Santa Monica, California were directly linked to each other. This was the first step in linking two computers, but packet switches had not been implemented yet. In 1967 the ACM Symposium on Operating Principles met to present a plan for a packet switching network. The ACM was the Association for Computing Machinery and is presently the oldest organization of computer scientists. The first design paper on the Advanced Research Projects Agency Network, or ARPANet, was published and presented at the Symposium. In 1968, the first PS network was presented to the Advanced Research Projects Agency.
The original theory behind ARPANet was conceived by the RAND Corporation during the Cold War. The strategic problem being presented was how the US authorities would communicate after a nuclear war. The apparent solution was to create a Wide Area Network, or WAN, made of interconnected nodes (computers), that would survive a nuclear war. This meant that if any US major city was destroyed by a nuclear bomb, the remaining cities would still have a means of communication through this network. However, no matter how deeply buried and armored the cables and switches were, a nuclear attack could easily wipe them out. Another problem was a matter of command and control. If there was some sort of location where the central processing took place, it would obviously be the first target of enemy attack. A bold proposal was made by Paul Baran in 1964. His solution was that the network would "have no central authority," and it would be "designed from the beginning to operate while in tatters." The principle was that the network would be unreliable at all times. It did not matter which route packets took to get to their destinations. They just wandered the network, from node to node, until they arrived at their final destination. If any particular part was blown away, the packets would meander through other nodes in other areas of the US.
Finally in1969, ARPANet, the precursor to the Internet, was officially commissioned by Department of Defense for research into networking. The first four computers making up ARPANet were connected. The first node was located at the University of California at Los Angeles, followed by the Stanford Research Institute, the University of California at Santa Barbara, and the University of Utah. By 1971, there were fifteen nodes. As the years progressed, the size of ARPANet increased. In its infancy, scientists and researches used it to trade information and access each other's facilities from hundreds of miles away. There was a strict work ethic instituted by ARPA. As the network matured, these people began to find other less productive uses for it, like sharing gossip and sending personal messages. This was generally looked down upon, but it was not long until the mailing list was invented.
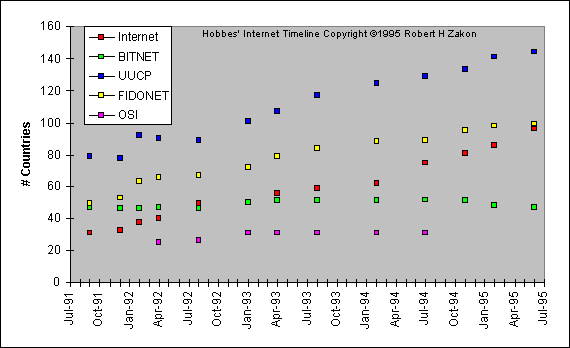
ARPANet's communication protocol was Network Control Protocol or NCP, which was later replaced by the more advanced TCP/IP protocol. By 1977 TCP/IP was being used by other networks to tap into ARPANet. These included Telenet (the first commercial version of ARPANet), UUCP (Unix-to-Unix CoPy developed at AT&T Bell Labs), USENET (established using UUCP), BITNET (the "Because It's Time Network"), FidoNet, and OSI (Department of Defense). These networks were all separate from each other, ARPANet, and the Internet, due simply to the fact that different types of people used them. Here are some charts and diagrams outlining the exponential growth of the Internet and the various other networks:
Figure: Internet Hosts
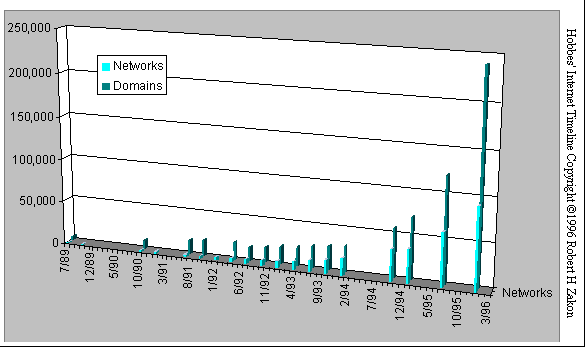
Figure: Internet Networks and Domains
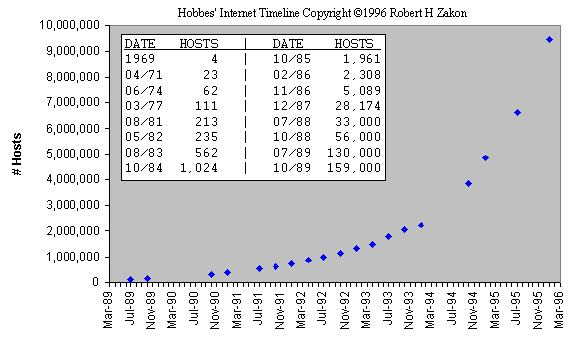
Figure: Worldwide Networks Growth
ARPANet was still tightly regulated in the seventies until its military part separated in 1982 and became MILENet. As TCP/IP continued to grow in popularity, the vast amount of other networks and linked machines began to slowly overshadow ARPANet. They constituted what became the Internet. What was left of ARPAnet had been replaced by the National Science Foundation network or NSFnet where scientists and researchers still collaborate over projects. In 1990, ARPANet ceased to exist.
*******
The advent of World Wide Web brought with it a handful of new Internet jargon, which, like most computer related terminology, comprises of seemingly cryptic acronyms. The three main terms are URLs, HTTP, and HTML. The center of our senior exhibition revolved around these three abbreviations.
URLs, or Uniform Resource Locators, are the means by which Internet server resources are named and addressed. They identify resources such as those from Gopher or FTP servers. World Wide Web hypertext documents use URLs to directly link themselves to other hypertext documents or resources. For example, the URL of the history department at Thacher is:
"http://www.thacher.pvt.k12.ca.us/thacher/history.html"
All URLs follow a similar pattern. The first text string is the protocol (http:). The protocol is always indicated by the string appearing before the first colon. This is followed by a domain name (//www.thacher.pvt.k12.ca.us). The actual acronym of DOMAIN stands for Distributed Operating Multi Access Interactive Network. The domain name is the unique name that identifies an Internet site. They always have two or more parts, with each part separated by periods. From left to right, each part of a domain name usually goes from specific to general. In this case, with the exception of the "www" which is in many domain names, "thacher" is the most specific part followed by more and more general categories. It is possible for a computer to have several domain names but each domain name is attributed to only one computer. It is also possible for a domain name to exist but not be connected to an actual machine. This is often done so that a organization or business can have an Internet e-mail address without having to establish a real Internet site. In these cases, some real Internet machine or server must handle the mail for the given domain name. The domain names is sometimes followed by an additional port number (:####) for further identification purposes. Finally, the URL ends with directory and resource details (/thacher/history.html) that can be found within the given domain.
The second Web term is HTTP, or the Hypertext Transfer Protocol. This is the Internet protocol designed for the Web to distribute hypertext documents. Like the other Internet protocols such as FTP and Gopher, HTTP is a client-server protocol. There are several key differences between an HTTP server and an FTP server. HTTP servers not only return files from clients requests, but they also return information generated by programs on the server. Also the HTTP server processes information supplied by the client through programs on the server. When you load Netscape, NCSA Mosaic, or any other Web browser, there are four steps in an HTTP connection. First the client opens a connection by contacting the server at the Internet address and port number given by the URL. Next, the client makes a request for a service by sending a message to the server. The request is comprised of HTTP request headers that describe the method requested for the transaction and give information about the client and its capabilities. This is sometimes followed by data sent from the client to the server. Next, the server responds to the request through response headers the situation of the transaction followed by the actual data requested. The last step is closing the connection, which may be moving to a new URL, quitting the browser, or idling.
The third and last component of the Web is HTML code or the Hypertext Markup Language. This is the markup language or code behind all the Web pages that you encounter when browsing Web sites. It is the language with which hypertext documents are written and is what allows the creation of hypertext links, clickable graphics, and other types of interactive processes. HTML documents are almost like regular documents with one important addition: tags. These manipulate the document in such a way that allow the page creator to mark blocks of text as headings, lists, paragraphs, and so on. They mark and place images in their proper places. Most importantly, they are the key to hypertext links connecting the HTML document to other URLs on other FTP, Gopher, and HTTP servers. This allows you to click on underlined text or images and take you to other locations, perhaps on the opposite side of the globe.
The objective of our project was twofold. The first goal was to provide the various academic departments with research sources. The second goal was to learn the HTML source code and write well-organized documents. Because the Internet is always changing and new sites are appearing every day, there is no way that the first goal can ever be achieved completely. We did compile what we thought were some of the best sites that offered the most informative research material and sites that referred to other equally useful sites through hypertext links. This was a long and laborious process of chasing down links and looking over hundreds of sites. Each subject is accompanied by the necessary resources to begin research. The humanities and social sciences are supplied by a vast number of primary resources. The arts and sciences also have connections to laboratories, virtual textbooks, graphics libraries, and online museums. We accomplished our second goal accomplished successfully. Our pages turned out to be appealing graphically and well-organized. I had designed and arranged a large quantity of the artwork and graphics on the pages. This involved a lot of editing and changing between graphic file formats to ease editing. I also learned to write and implement HTML code to accommodate the graphics and text that our pages contained. Personally, I was able to grasp the essentials of HTML code and become fairly proficient in Web editing.
One of the challenges in HTML coding is simply writing good documents. This involves writing documents that are technically correct and making the right decisions about design elements of the page. These means that the page must be displayed correctly as the coder planned, and that it must be appealing and presented clearly to the user without any clutter. The main challenge we faced was finding URLs that might be useful for research. If we did come across a potentially useful source of information, we then had to examine it and assess its usefulness. If its content lacked any pertinent information regarding a particular subject, we threw it away and began our search again. Some of the setbacks that hindered our progress were the slowing down of the school server, Internet traffic (many users online) which slowed the searching and loading of Web pages considerably, and searches that resulted in absolutely nothing. We began our search with any one of the popular search engines on the Web. On these search engines you simply type in your query and it spits back all the sites with the matching word or words in your query. As you can imagine this is a highly inefficient way of trying to find information because there will inevitably be hundreds of documents that may contain your search string and have no relevant information related to the query. For example, I was looking for US history primary source material so I went to a familiar reliable search engine at http://altavista.digital.com. I entered the query "US history primary sources" and out came the first ten entries of that search. About every one of those sites came from the same college. When I clicked on each URL, I was taken to an Web page giving out the weekly assignments for US history at the college. Even though I had just begun searching I was already frustrated by this fruitless search. I knew that we would encounter many futile searches like this later.
Other problems arose from different machines trying to view our page. The buttons I had created for our main index page showed strange discolorations on machines running 256 colors or lower. The backgrounds that appeared white on the computer I was working on showed gray specks on other computers. Many design errors appeared as I opened the page on monitors running on higher resolutions. This meant that items on our page would appear perfectly fine on our page, but ended up being misplaced on other machines. Problems like these meant that we had to do a lot of moving between all types of Mac and PC computers to make sure that our page loaded correctly.
The main thing that worked in our advantage was finding sites that contained chunks of practical information and links to other useful URLs. The only drawback to finding these treasure troves was sorting the information out, assessing the value of the information, and organizing what was thought to be the most interesting and meaningful information. Also we cannot really complain at all for a slow network, since many home Internet users are confined to modems, which are snails compared to the speed of our network connection. Using the right HTML editor, is an integral part in writing organized code efficiently. We were using an excellent HTML editor called Hot Dog that actually helped to teach me the code as I used it. It resembled a word processor in that it contained functions that helped to manipulate the source by adding the necessary tags. However, when we upgraded our editor, we found that the upgrade was actually worse than our original editor, in that many useful functions were moved off the toolbar, and it was slower and less stable.
Much of the code I had learned did not come from extensively researching HTML guide books, but instead it came from necessity. Whenever I wanted to organize the page in a certain way, I would then refer to the guide books or look at other HTML documents on the Web. For instance, some of our pages turned out to be very long vertically, so we needed a way to have the user access those parts quickly. I first referred to a Web page that utilized this function, but I could not figure out how it worked. I then went to the HTML source book, but the problem was I did not know the name of the function. However, it took only about ten minutes of milling around in the index to find that "fragment identifiers" were the key to linking different parts of the HTML document. The categorizing of individual pages also required internal organization, so we found that table were the key. We also learned how to set up tables as we needed them.
In conclusion, I hope that our project is something that other interested people may want continue in the future. Because the Internet is always changing, our research page will always need to be updated every now and then to accommodate those changes. I also hope that our Web page provides a valuable tool for students who do not have the time to search for information on the Internet or who cannot find resources for their topics in the library. I learned a great deal about the technical aspects of the Internet, the history behind the Internet, and the process of creating appealing and useful Web documents. Ultimately, I hope this project provides students with the vital starting point they will need to research on the Internet and dispel any fears and misconceptions about the vast world of the Internet.
Bennett, Steve. (1994) Guide to Web Terminology [Online].
Available World Wide Web: www.euro.net/innovation/Web_Word_Base/Dictionary.html
Flynn, Peter. (date unknown) The WorldWideWeb Acronym and Abbreviation Server [Online]. Available World Wide Web: www.ucc.ie/info/net/acronyms/acro.html
Enzer, Matisse, and Internet Literacy Consultants. (1995) ILC Glossary of Internet Terms [Online]. Available World Wide Web: www.matisse.net/files/glossary.html
Graham, Ian S. HTML Sourcebook. New York: John Wiley & Sons, Inc., 1995.
The Internet Training and Development Centre (1994) Chronology [Online]. Available World Wide Web: www.outreach.org/main/ottgp/fred/whatis/part-6.htm
Sterling, Bruce. (1993) Short History of the Internet [Online]. Available World Wide Web: w3.aces.uiuc.edu/AIM/SCALE/nethistory.html
Texas A&M Student Chapter of The Association for Computing Machinery. (date unknown) What is ACM? [Online]. Available World Wide Web: www.cs.tamu.edu/student-org/acm/acminfo.html
Zakon, Robert H'obbes.' (1996) Hobbes' Internet Timeline v2.4a [Online]. Available World Wide Web: info.isoc.org/guest/zakon/Internet/History/HIT.html